So where to begin with this series I started on Learning Analytics and AI? The first post started with a basic and over-simplified view of the very basics. I guess the most logical place to jump to is… the leading edge of the AI hype? Well, not really… but there is an event in that area happening this week, so I need to go there anyways.
I was a bit surprised that the first post got some attention – thank you to those that read it. Since getting booted out of academia, I have been unsure of my place in the world of education. I haven’t really said much publicly or privately, but it has been a real struggle to break free from the toxic elements of academia and figure out who I am outside of that context. I was obviously surrounded by people that weren’t toxic, and I still adjunct at a university that I feel supports its faculty… but there were still other systemic elements that affect all of us that are hard to process once you are gone.
So, anyway, I just wasn’t sure if I could still write anything that made a decent point, and I wasn’t too confident I did that great of a job writing about such a complex topic in a (relatively) short blog post last time. Maybe I didn’t, but even a (potentially weak) post on the subject seems to resonate with some. Like I said in the last post, I am not the first to bring any of this up. In fact, if you know of any article or post that makes a better point than I do, please feel free to add it in the comments.
So, to the topic at hand: this week’s Empowering Learners in the Age of AI conference in Australia. My concern with this conference is not with who is there – it seems to be a great group of very knowledgeable people. I don’t know some of them, but many are big names in the field that know their stuff. What sticks out to me is who is not there, as well as how AI is being framed in the brief descriptions we get. But neither of those points is specific to this conference. In fact, I am not really looking at the conference as much as some parts of the field of AI, with the conference just serving as proof that the things I am looking at are out there.
So first of all, to address the name of the conference. I know that “empowering learners” is a common thing to say not just in AI, but education in general. But it is also a very controversial and problematic concept as well. This is one concern that I hang on all of education and even myself as I like the term “empower” as well. No matter what my intentions (or anyone else’s), the term still places the institution and the faculty as the center of the power in the learning process – there to decide whether the learners get to be empowered or not. One of the best posts on this topic is by Maha Bali: The Other Side of Student Empowerment in a Digital World. At the end of the post, she gets to some questions that I want to ask of the AI field, including these key ones:
“In what ways might it reproduce inequality? How participatory has the process been? How much have actual teachers and learners, especially minorities, on the ground been involved in or consulted on the design, implementation, and assessment of these tools and pedagogies?”
I’ll circle back to those throughout the post.
Additionally, I think we should all question the “Age of AI” and “AI Society” part. It is kind of complicated to get into what AI is and isn’t, but the most likely form of AI we will see emerge first is what is commonly called “Artificial General Intelligence” (AGI), which a is deceptive way of saying “pretending to act like humans but not really be intelligent like we are.” AGI is really a focus on creating something that “does” the same tasks humans can, which is not what most people would attribute to an “Age of AI” or “AI Society.” This article on Forbes looks at what this means, and how experts are predicting that we are 10-40 years away from AGI.
Just as an FYI, I remember reading in the 1990s that we were 20-40 years away from AGI then as well.
So we aren’t near an Age of AI, probably not in many of our lifetimes, and even the expert options may not end up being true. The Forbes articles fails to mention that there were many problems with the work that claimed to be able to determine sexuality from images. In fact, there is a lot to be said about differentiating AI from BS that rarely gets brought up by the AI researchers themselves. Tristan Greene best sums it up in his article about “How to tell the difference between AI and BS“:
“Where we find AI that isn’t BS, almost always, is when it’s performing a task that is so boring that, despite there being value in that task, it would be a waste of time for a human to do it.”
I think it would have been more accurate to say you are “bracing learners for the age of algorithms” than empowering for an age of AI (that is at least decades off but may never actually happen according to some). But that is me, and I know there are those that disagree. So I can’t blame people for being hopeful that something will happen in their own field sooner than it might in reality..
Still, the most concerning thing about the field of AI is who is not there in the conversations, and the Empowering Learners conference follows the field – at least from what I can see on their website. First of all, where are the learners? Is it really empowering for learners when you can’t really find them on the schedule or in the list of speakers and panelists? Why is their voice not up front and center?
Even bigger than that is the problem that has been highlighted this week – but one that has been there all along:
The specific groups she is referring to are BIPOC, LGBTQA, and Disabilities. We know that AI has discrimination coded into it. Any conference that wants to examine “empowerment” will have to make justice front and center because of long existing inequalities in the larger field. Of course, we know that different people have different views of justice, but “empowerment” would also mean each person that faces discrimination gets to determine what that means. Its really not fair to hold a single conference accountable for issues that long existed before the conference did, but by using the term “empowerment” you are setting yourself up to a pretty big standard.
And yes, “empowerment” is in quotes because it is a problematic concept here, but it is the term the field of AI and really a lot of the world of education uses. The conference web page does ask “who needs empowering, why, and to do what?” But do they mean inequality? And if so, why not say it? There are hardly any more mentions of this question after it is brought up, much less anything connecting the question to inequality, in most of the rest of the program. Maybe it will be covered in conference – it is just not very prominent at all as the schedule stands. I will give them the benefit of the doubt until after the conference happens, but if they do ask the harder questions, then they should have highlighted that more on the website.
So in light of the lack of direct reference to equity and justice, the concept of “empowerment” feels like it is taking on the role of “equality” in those diagrams that compare “equality” with “equity” and “justice”:
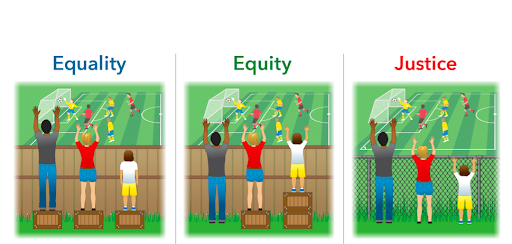
(This adaption of the original Interaction Institute for Social Change image by Angus Macguire was found on the Agents of Good website. Thank you Alan Levine for helping me find the attribution.)
If you aren’t going to ask who is facing inequalities (and I say this looking at the fields of AI, Learning Analytics, Instructional Design, Education, all of us), then you are just handing out empowerment the same to all. Just asking “who needs empowering, why, and to do what?” doesn’t get to critically examining inequality.
In fact, the assumption is being made by so many people in education that you have no choice but to utilize AI. One of the best responses to the “Equality vs Equity vs Justice” diagrams has come from Bali and others: what if the kids don’t want to play soccer (or eat an apple or catch a fish or whatever else is on the other side of the fence in various versions)?
Resistance is a necessary aspect of equity and justice. To me, you are not “empowering learners” unless you are teaching them how to resist AI itself first and foremost. But resistance should be taught to all learners – even those that “feel they are safe” from AI. This is because 1) they need to stand in solidarity with those that are the most vulnerable, to make sure the message is received, and 2) they aren’t as safe as they think.
There are many risks in AI, but are we really taking the discrimination seriously? In the linked article, Princeton computer science professor Olga Russakovsky said
“A.I. researchers are primarily people who are male, who come from certain racial demographics, who grew up in high socioeconomic areas, primarily people without disabilities. We’re a fairly homogeneous population, so it’s a challenge to think broadly about world issues.”
Additionally, (now former) Google researcher Timnit Gebru said that scientists like herself are
“some of the most dangerous people in the world, because we have this illusion of objectivity.”
Looking through the Empowering Learner event, I don’t see that many Black and Aboriginal voices represented. There are some People of Color, but not near enough considering they would be the ones most affected by discrimination that would impede any true “empowerment.” And where are the experts on harm caused by these tools, like Safiya Noble, Chris Gilliard, and many others? The event seems weighted towards those voices that would mostly praise AI, and it is a very heavily white set of voices as well. This is the way many conferences are, including those looking at education in general.
Also, considering that this is in Australia, where are the Aboriginal voices? Its hard to tell on the schedule itself. I did see on Twitter that the conference will start with an Aboriginal perspective. But when is that? In the 15 minute introductory session? That is no where near enough time for that. Maybe they are elsewhere on the schedule and just not noted well enough to tell. But why not make that a prominent part of the event rather than part of a 15 minute intro (if that is what it is)?
There are some other things I want to comment on about the future of AI in general:
- The field of AI is constantly making references to how AI is affecting and improving areas such as medicine. I would refer you back to the “How to tell the difference between AI and BS” article for much of that. But something that worries me about the entire AI field talking this way is that the are attributing “artificial intelligence” to things that boil down to advanced pattern recognition mainly using human intelligence. Let’s take, for example, recognizing tumors in scans. Humans program the AI to recognize patterns in images that look like tumors. Everything that the AI knows to look for comes directly from human intelligence. Just because you can then get the algorithm to repeat what the humans programmed it to thousands of times per hour, that doesn’t make it intelligence. It is human intelligence pattern recognition that has been digitized, automated, and repeated rapidly. This is generally what is happening with AI in education, defense, healthcare, etc.
- Many leaders in education in general like to say that “institutions are ill-prepared for AI” – but how about how ill-prepared AI is for the equity and reality?
- There is also often talk in the AI community about building trust between humans and machines that we see examples of at the conference as well: “can AI truly become a teammate in group learning or a co-author of a ground-breaking scientific discovery?” I don’t know what the speaker plans to say, but the answer is no. No we shouldn’t build trust and no we shouldn’t anthropomorphize AI. We should always be questioning it. But we also need to be clear, again, that AI is not the one that is writing (or creating music or paintings). This is the weirdest area of AI – they feed a bunch of artistic or music or literary patterns into AI, tell it how to assemble the patterns, and when something comes out it is attributed to AI rather than the human intelligence that put it all together. Again, the machine being able to repeat and even refine what the human put there in the first place is not the machine creating it. Take, for example, these different AI generated music websites. People always send these to me and say “look how well the machine put together ambient or grindcore music or whatever.” Then I listen… and it is a mess. They take grindcore music and chop it up in to bits and then run those bits through pattern recognition and spit out this random mix – that generally doesn’t sound like very good grindcore. Ambient music works the best to uninitiated ears, but to fans of the music it still doesn’t work that great.
- I should also point out about the conference that there is a session on the second day that asks “Who are these built for? Who benefits? Who has the control?” and then mentions “data responsibility, privacy, duty of care for learners” – which is a good starting point. Hopefully the session will address equity, justice, and resistance specifically. The session, like much of the field of AI, rests on the assumption that AI is coming and there is nothing you can do to resist it. Yes the algorithms are here, and it is hard to resist – but you still can. Besides, experts are still saying 10-40 years for the really boring stuff to emerge as I examined above.
- I also hope the conference will discuss the meltdown that is happening in AI-driven proctoring surveillance software.
- I haven’t gotten much into surveillance yet, but yes all of this relies on surveillance to work. See the first post. Watch the Against Surveillance Teach-In Recording.
- I was about to hit publish on this when I saw an article about a Deepfake AI Santa that you can make say whatever you want. The article says “It’s not nearly as disturbing as you might think”… but yes, it is. Again, people saying something made by AI is good and realistic when it is not. The Santa moves and talks like a robot with zero emotion. Here again, they used footage of a human actor and human voice samples and the “AI” is an algorithm that chops it up into the parts that makes your custom message. How could this possibly be misused?
- One of the areas of AI that many in the field like to hype are “conversational agents” aka chatbots. I want to address that as well since that is an area that I have (tried) to research. The problem with researching agents/bots is that learners just don’t seem to be impressed with them – it’s just another thing to them. But I really want to question how these count as AI after having created some myself. The process for making a chatbot is that you first organize a body of information into chunks of answers or statements that you want to send as responses. You then start “training” the AI to connect what users type into the agent (aka “bot”) with specific statements or chunks of information. The AI makes a connection and sends the statement or information or next question or video or whatever it may be back to the user. But the problem is, the “training” is you guessing dozens of ways that the person might ask a question or make a statement (including typos or misunderstandings) that matches with the chunk of information you want to send back. You literally do a lot of the work for the AI by telling it all the ways someone might type something into the agent that matches each chunk of content. They want at least 20 or more. What this means is that most of the time, when you are using a chatbot, it gives you the right answer because you typed in one of the most likely questions that a human guessed and added to the “training” session. In the rare cases where some types something a human didn’t guess, then the Natural Language Processing kicks in to try and guess the best match. But even then it could be a percentage of similar words more than “intelligence.” So, again, it is human intelligence that is automated and re-used thousands of times a minute – not something artificial that has a form of intelligence. Now, this might be useful in a scenario when you have a large body of information (like an FAQ bot for the course syllabus) that could use something better than a search function. Or maybe a branching scenarios lesson. But it takes time to create a good chatbot. There is still a lot of work and skill to creating the questions and responses well. But to use chatbots for a class of 30, 50, 100? You probably will spend so much time making it that it would be easier to just talk to your students.
- Finally, please know that I realize that what I am talking about still requires a lot of work and intelligence to create. I’m not doubting the abilities of the engineers and researchers and others that put their time into developing AI. I’m trying to get at the pervasive idea that we are in an Age of AI that can’t be avoided. Its a pervasive idea that was even made in a documentary web series a year ago. I also question whether “artificial intelligence” is the right term for all of this, rather than something more accurate like “automation algorithms.”
 Again, everything I touch on here is not as much about this conference, as it is about the field of AI since this conference is really just a lot of what is in the AI field concentrated into two days and one website. The speakers and organizers might have already planned to address everything I brought up here a long time ago, and they just didn’t get it all on the website. We will see – there are some sessions with no description and just a bio. But still, at the core of my point, I think that educators need to take a different approach to AI than we have so far (maybe by not calling it that when it rarely is anything near intelligent) by taking justice issues seriously. If the machine is harming some learners more than others, the first step is to teach resistance, and to be successful in that all learners and educators need to join in the resistance.
Again, everything I touch on here is not as much about this conference, as it is about the field of AI since this conference is really just a lot of what is in the AI field concentrated into two days and one website. The speakers and organizers might have already planned to address everything I brought up here a long time ago, and they just didn’t get it all on the website. We will see – there are some sessions with no description and just a bio. But still, at the core of my point, I think that educators need to take a different approach to AI than we have so far (maybe by not calling it that when it rarely is anything near intelligent) by taking justice issues seriously. If the machine is harming some learners more than others, the first step is to teach resistance, and to be successful in that all learners and educators need to join in the resistance.
Matt is currently an Instructional Designer II at Orbis Education and a Part-Time Instructor at the University of Texas Rio Grande Valley. Previously he worked as a Learning Innovation Researcher with the UT Arlington LINK Research Lab. His work focuses on learning theory, Heutagogy, and learner agency. Matt holds a Ph.D. in Learning Technologies from the University of North Texas, a Master of Education in Educational Technology from UT Brownsville, and a Bachelors of Science in Education from Baylor University. His research interests include instructional design, learning pathways, sociocultural theory, heutagogy, virtual reality, and open networked learning. He has a background in instructional design and teaching at both the secondary and university levels and has been an active blogger and conference presenter. He also enjoys networking and collaborative efforts involving faculty, students, administration, and anyone involved in the education process.


